Using RAG Evaluators
On this page, you will learn how to configure and use RAG evaluators for your custom-built application. RAG evaluators are unique because they need intermediate outputs and internal variables (such as context) to run.
By the end of this tutorial, you will know how to write a RAG application that saves the required internal variables and how to configure the evaluator in Agenta to use these in evaluation.
Access to internal variables (internals) and intermediate outputs (traces or inline traces) requires version 0.20.0+ of the Python SDK.
Access to RAG Evaluators and view trace in the Web UI requires Agenta Cloud and is not available in Agenta OSS.
Developing the RAG Application
Let's consider a simple RAG Application (the source code can be found here).
The application fetches count movies on the topic of topic within the genre of genre, then generates an initial summary from those movies, and finally summarizes the report twice in a row, arbitrarily.
async def rag(topic: str, genre: str, count: int = 5):
result = await retriever(topic, genre, count)
result = await reporter(topic, genre, count, result["movies"])
result = await summarizer(topic, genre, result["report"])
result = await summarizer(topic, genre, result["report"])
return result["report"]
The retriever simply performs semantic search on the formatted prompt fetched from Agenta.
async def retriever(topic: str, genre: str, count: int) -> dict:
prompt = ag.config.retriever_prompt.format(topic=topic, genre=genre)
topk = count * ag.config.retriever_multiplier
query = embed(prompt)
result = search(query["embedding"], topk)
movies = [
f"{movie['title']} ({movie['year']}) in {movie['genres']}: {movie['plot']}"
for movie in result
]
return {"movies": movies}
The reporter processes the set of movies retrieved in the previous step and generates a report.
async def reporter(topic: str, genre: str, count: int, movies: dict) -> dict:
context = ag.config.generator_context_prompt.format(movies="\n".join(movies))
instructions = ag.config.generator_instructions_prompt.format(
count=count, topic=topic, genre=genre
)
prompts = {"system": context, "user": instructions}
opts = {
"model": ag.config.generator_model,
"temperature": ag.config.generator_temperature,
}
result = await chat(prompts, opts)
report = result["message"]
return {"report": report}
The summarizer finally improves on the reporter's output, in two passes.
async def summarizer(topic: str, genre: str, report: dict) -> dict:
context = ag.config.summarizer_context_prompt
instructions = ag.config.summarizer_instructions_prompt.format(
topic=topic, genre=genre, report=report
)
prompts = {"system": context, "user": instructions}
opts = {
"model": ag.config.summarizer_model,
"temperature": ag.config.summarizer_temperature,
}
result = await chat(prompts, opts)
report = result["message"]
return {"report": report}
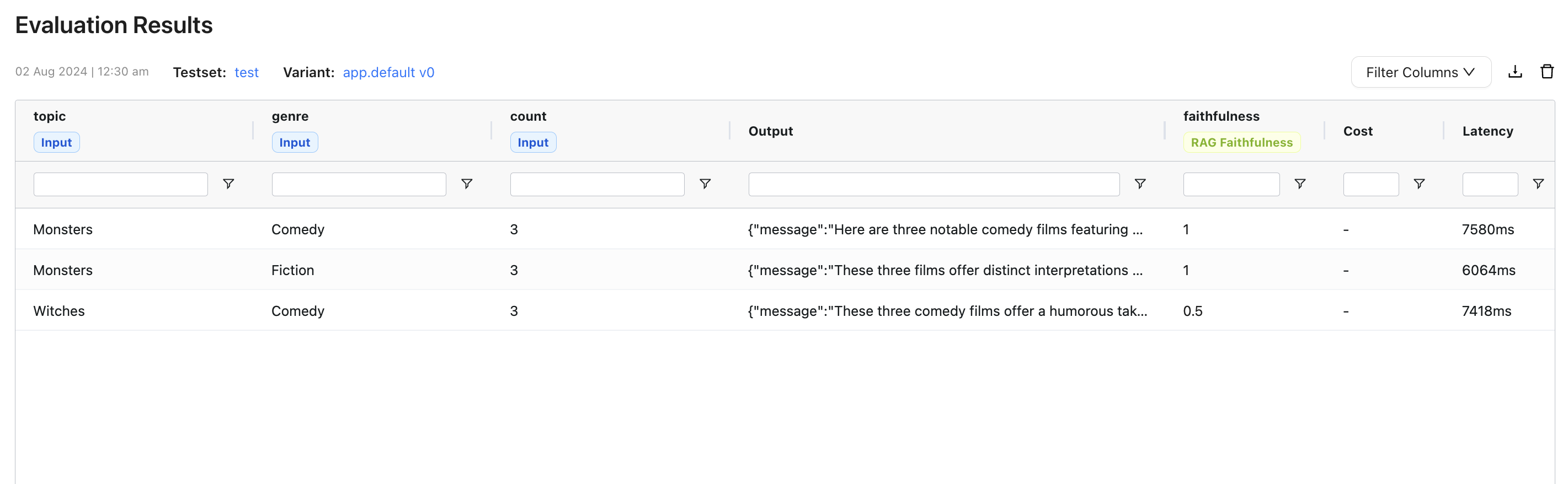
Testing the RAG Avaluation
Upon instrumenting and serving the RAG Application with Agenta, you should see the output of the second summarizer.


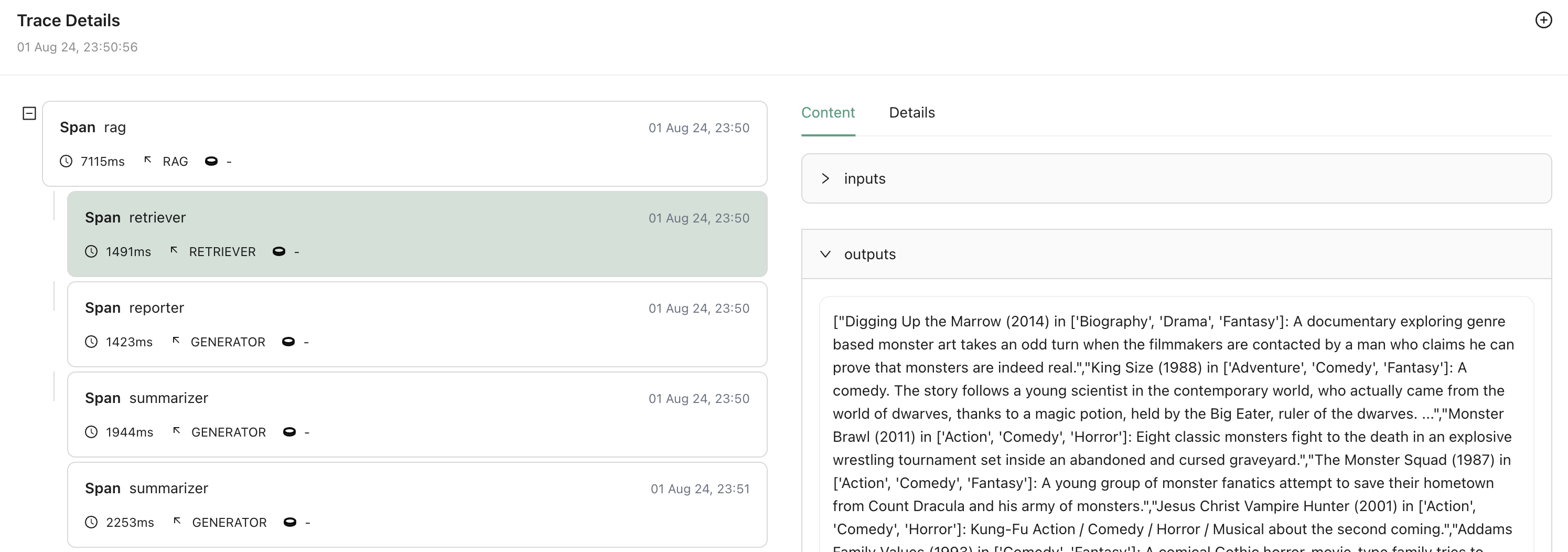
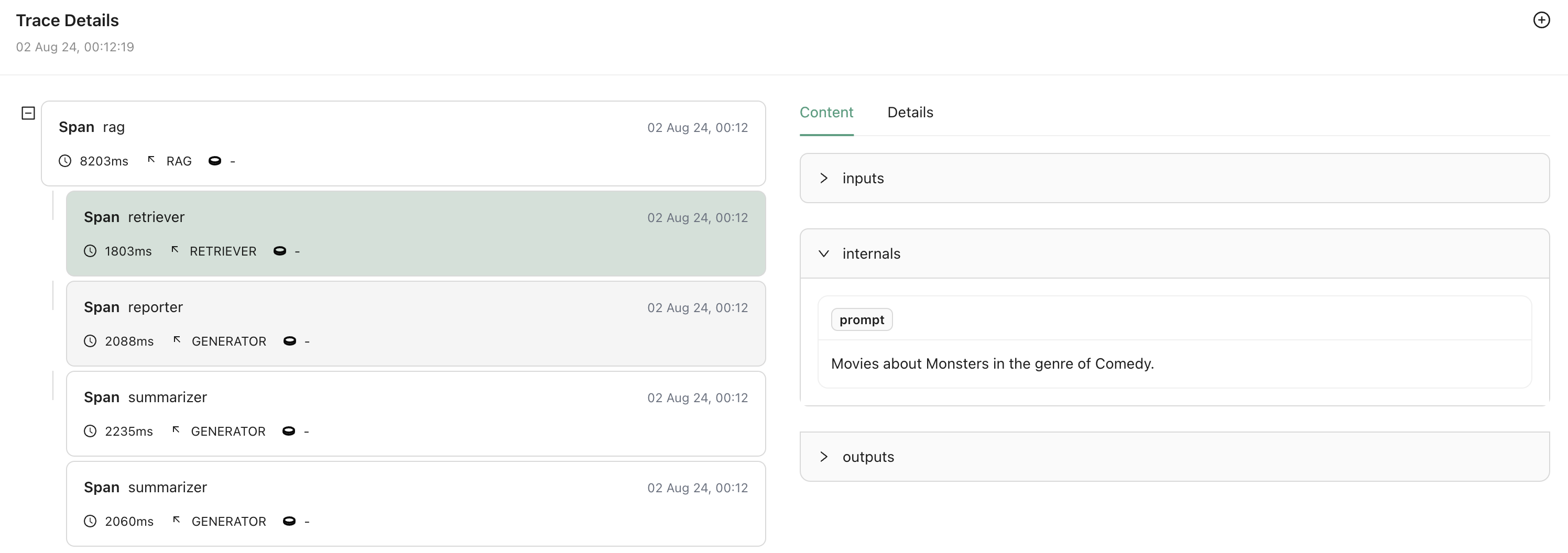
Upon clicking on view trace, you should be able to see the inputs and outputs for each instrumented stage in the RAG workflow.
Now that we have a RAG Application, let's create a RAG evaluator.
Creating the RAG Evaluator
On the evlauators page, click on RAG Faithfulness for example.
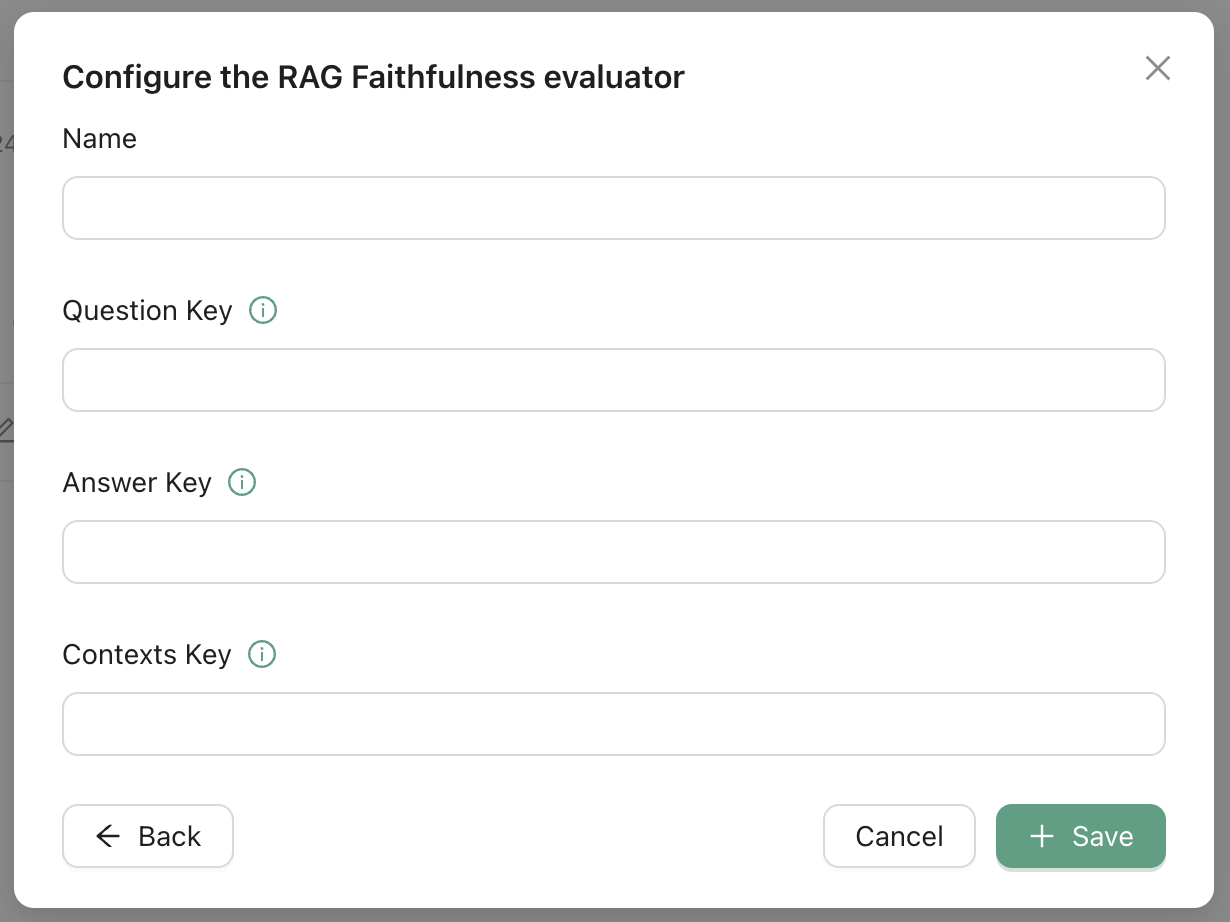
RAG evaluators, based on RAGAS are different from other evaluators in Agenta in that they
often require internal variables. For instance,
Faithfulness and Context
Relevancy both require question, answer,
and contexts.
From the trace we saw before, we could say that answer maps to the second rag summarizer output report, denoted by rag.summarizer[1].outputs.report. Similarly, the contexts map to the rag retriever output movies, denoted by rag.retriever.outputs.movies.
However, the question, which corresponds to the formatted prompt sent to the retriever (or the reporter) is not part of the inputs or the outputs of any stage in the workflow.
Next, let's see how and where you to find that variable.
Updating the RAG Application
In Agenta, when instrumenting stages of a workflow, there is a utility to add internal variables, called internals, to the stage's span.
async def retriever(topic: str, genre: str, count: int) -> dict:
prompt = ag.config.retriever_prompt.format(topic=topic, genre=genre)
topk = count * ag.config.retriever_multiplier
ag.tracing.store_internals({"prompt": prompt})
query = embed(prompt)
result = search(query["embedding"], topk)
movies = [
f"{movie['title']} ({movie['year']}) in {movie['genres']}: {movie['plot']}"
for movie in result
]
return {"movies": movies}
The utility ag.tracing.store_internals(...), as shown in the snippet above.
Upon serving the RAG Application again, the trace should now contain the formatted prompt
We are ready to resume the configuration of our RAG Evaluator.
Configuring the RAG Evaluator
Back to the evaluators page, we can now map the question to the rag retriever internal prompt, denoted by rag.retriever.internals.prompt, as shown below.
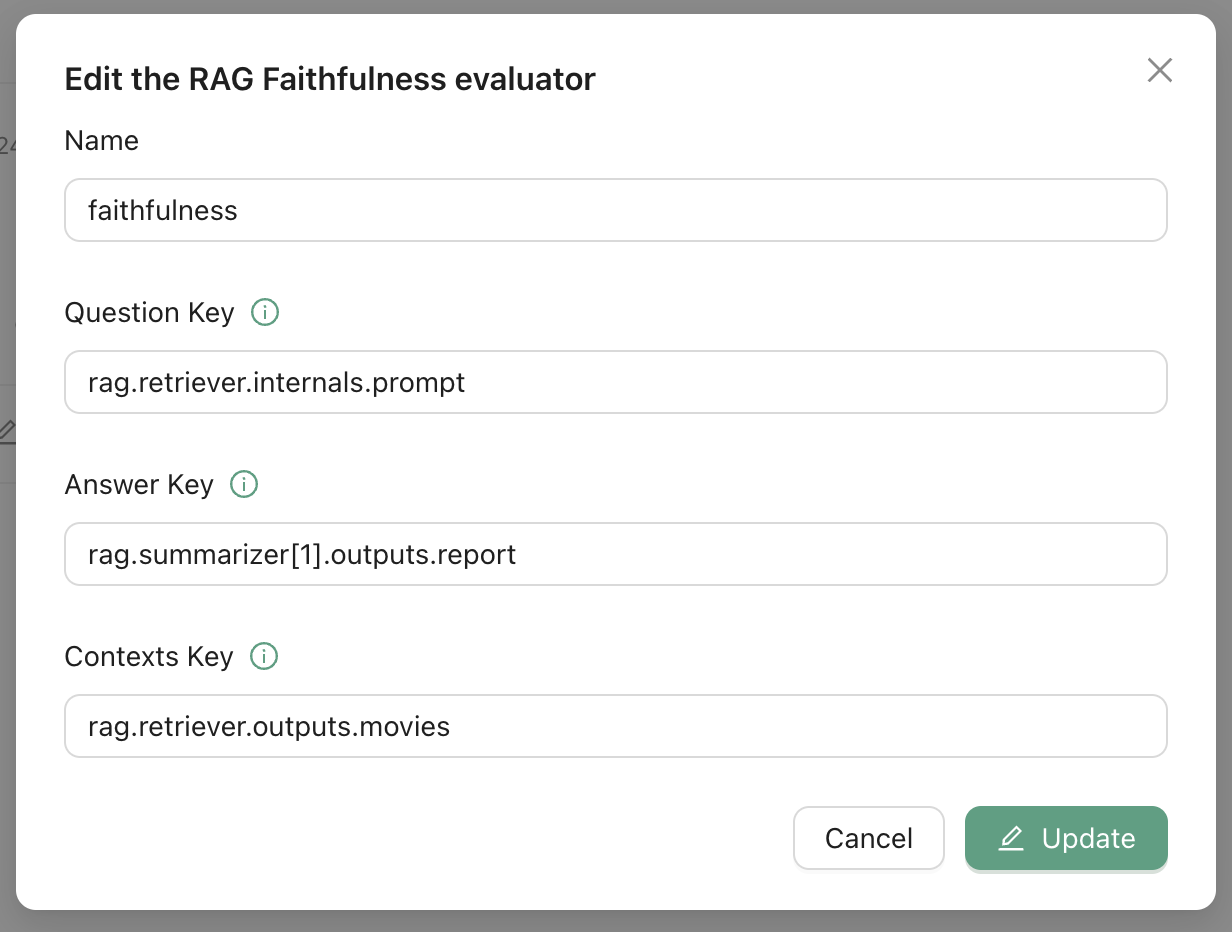
Once the RAG Evaluator is set up, you are ready to go.
Running the evaluation
You can now run evaluations on RAG Applications based on RAG Evaluators.